2025 brought us the new idiom for building AI (beginning with Manus and Claude Code): give it tools to operate a computer. This is a break from the past default approach represented by ChatGPT, which is LLM + a menu of bespoke API connections to plug in to various systems of record.
At Raycaster, we build document agents and run rigorous evaluations for agent companies to help them hillclimb on complex professional tasks. Because we spend our days watching agents try—and often fail—to navigate messy corporate archives, we've had to rethink how an AI interacts with files.
The limits of plaintext
Our first attempt at a document agent was to ingest documents, parse them into plaintext pages, expose search/read/write tools, and let the LLM operate over virtual directories of artifacts and pages backed by a SQL database.
This immediately worked for agentic navigation and observational tasks, but quickly fell apart when it came to multimodality and editing: users bring complex Word and PDF files with tables and charts, for which even frontier VLM-based OCR approaches can only do so much (reading a textual description of a chart isn't the same as seeing the chart), not to mention subtle layout and formatting such as text coloring, which is often lost in the process. While perfectly adequate for a corporate knowledge base, our setup could not realistically ingest a rich-format Word document, reason and edit over it, then spit out a usable revision as a deliverable.
Giving agents a real computer
Our next iteration was to let the document agent work on a real computer, more like a coding agent on files than tool calls over a database — coding is a general ability of an LLM, not a specialty feature. Coding to an LLM is what a pair of deft hands is to a person; it's just an advanced form of file editing. Modern LLMs reach for pandoc to convert a Word document into something they can more easily read, unpack a .docx's underlying data to access an embedded image, and they absolutely want Python on hand to pull numbers from the third sheet of an Excel report at a moment's notice. We gave agents a Linux environment in the cloud, with a useful toolchain pre-installed, and mounted users' documents from cloud object storage into that filesystem (often via FUSE; AWS has since packaged the pattern as S3 Files). Once the LLM has Bash and those mounts, the bottleneck shifted to review.

Wrong until merge
Combined with good document skills (such as Anthropic's), this solved the capability problem. But the AI isn't me. When I look at the changes an LLM proposes to a document, more often than not I'll disagree: they are usually on point but almost never exactly what I would have written. Conventional wisdom is to gate write-capable tools behind human approval, but once the human is confirming individual tool calls, the promise of autonomy is gone.
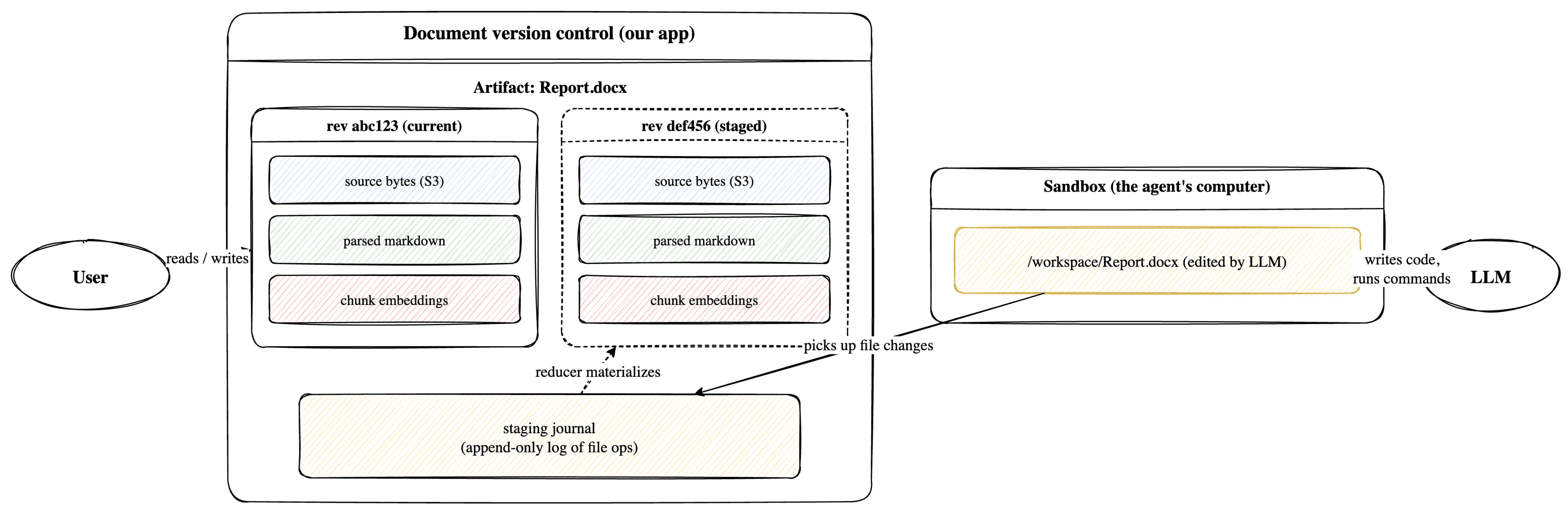
Coding agents already show us where this ends: power users eventually switch to the dangerously-skip-permissions camp for the benefit of full autonomy. Not that developers are reckless, but because the agent is working inside a git branch where bad changes can be identified and thrown away. Document agents need the same kind of layer underneath, not another “review changes as you go and make sure they're correct”. The AI is allowed to be wrong until a human merges. When the agent edits /workspace/Report.docx, it should not touch the user's canonical Report.docx — only a candidate revision to review.
For coding agents, this is easy: source code is plaintext, and an LLM reads and produces patches directly. Documents are different. A .docx is a zipped XML database LLMs can't directly read, while LLM-friendly views are derived — parsed markdown, semantic-search chunks, extracted tables and figures. When Report.docx becomes a new revision, those views must recompute from the staged copy while the committed revision stays visible to everyone else. Nothing off the shelf did this, so we built a patch chain like git commits — one per agent turn, replayable on the committed source of truth — with parsed artifacts and vector indices keyed by content hash so staged and committed derived state don't clobber each other.
What we need now is GitHub
While software engineers complain that traditional git infrastructure like GitHub isn't keeping up with the volume of LLM-produced code and warrants a rethink, the world of document-heavy general knowledge work, on the other hand, hasn't even gotten its GitHub yet. That shows up fast when several agents touch the same deck — Report_v10.docx, then Report_v10_agent.docx, then a redline PDF in the cloud workspace.
It's tempting to look at adoption of AI in knowledge work and think the bottleneck is plumbing, where more tools, more integrations, eventually a complete-enough toolbelt that the agent can do a human's work as a 1:1 replacement. Once the agent already has a real machine, the obvious investment is better document skills and tighter integrations. But what teams still need underneath is what git gave code. That is what we ended up building, similar to GitHub, a refactor of how high-stakes document work is packaged, represented, and wired into a CI system for semantic review.
This is the future we're betting on, and we are curious to learn what you think.

