If you want to know if an AI model is smart, you ask it a riddle. If you want to know if an AI agent can do real work, you drop it into a hostile, uncurated document environment and see if it survives.
That is why we evaluate on OfficeQA Pro (often referred to as OfficeQA Hard). It is not a trivia suite. It is a grueling, grounded-reasoning benchmark built on a century of U.S. Treasury Bulletins—a labyrinth of tens of thousands of pages, heavy tabular layouts, and retroactive restatements. The agent must search the archive, locate the right data across multiple issues, perform the correct arithmetic, and output a specific number.
It is the kind of needle-in-a-haystack analysis where even human annotators struggle, averaging just ~35% accuracy when searching the full corpus. It requires exactly the kind of discipline that a chat interface cannot provide: anchoring the era, extracting the right row, and showing verifiable work under a deterministic grader.
Real work isn't about whether a model can generate a plausible answer. It's about whether the system can complete a verifiable task in a corpus that fights back.
Building a document-native agent
When evaluating Raycaster on OfficeQA Hard, we made a deliberate choice: we kept the underlying PDF parser exactly the same as the benchmark authors' setup. By holding the ingestion layer fixed—garbled headers, orphaned cells, and all—we isolated the impact of our agent architecture.
Under these constraints, our document agent pushes Gemini 3 Flash to State-of-the-Art (SOTA) on OfficeQA Pro.
This performance comes from treating document analysis like software engineering. We don't rely on the model to "memorize" or passively hallucinate an answer. Instead, we built search and retrieval primitives that give the agent absolute control over the context window.
A counterintuitive lesson from our traces is that embedding similarity is not enough. In an archive spanning most of a century, a vague vector query can return highly relevant paragraphs from the wrong decade. We mitigate this by forcing the agent to compose tools deliberately: using grep-style exact search to anchor on specific years and tables before relying on semantic retrieval.
We also deploy subagents and explicit task lists to act as latency and thrash reducers. Subagents isolate tasks, shrinking the context window and localizing failures so a single thread isn't trying to browse, search, and compute simultaneously.
We often explain this architecture using coding analogies:
- Design before you blast the repo: Anchor the era and document class before leaning on embeddings.
- Do not ship without a check: Re-read definitions, restatement rows, and numeric tolerances.
- Use the REPL: Run deterministic Python for statistics instead of hand-waving arithmetic.
- Ripgrep is not embarrassing: Exact symbolic anchors routinely beat unconstrained vector rank.
Results
Under the strict reward.py scoring regime, our best configuration reaches 80 of 133 correct—about 60.2% accuracy.
For direct comparison, the OfficeQA Pro paper reports Claude Opus 4.6 at 57.1%, GPT-5.4 at 51.1%, and a baseline Gemini 3 Flash at 33.1% on this exact setup. Our Gemini 3 Flash, running inside Raycaster's document-native harness, outperforms every model row in that sweep.
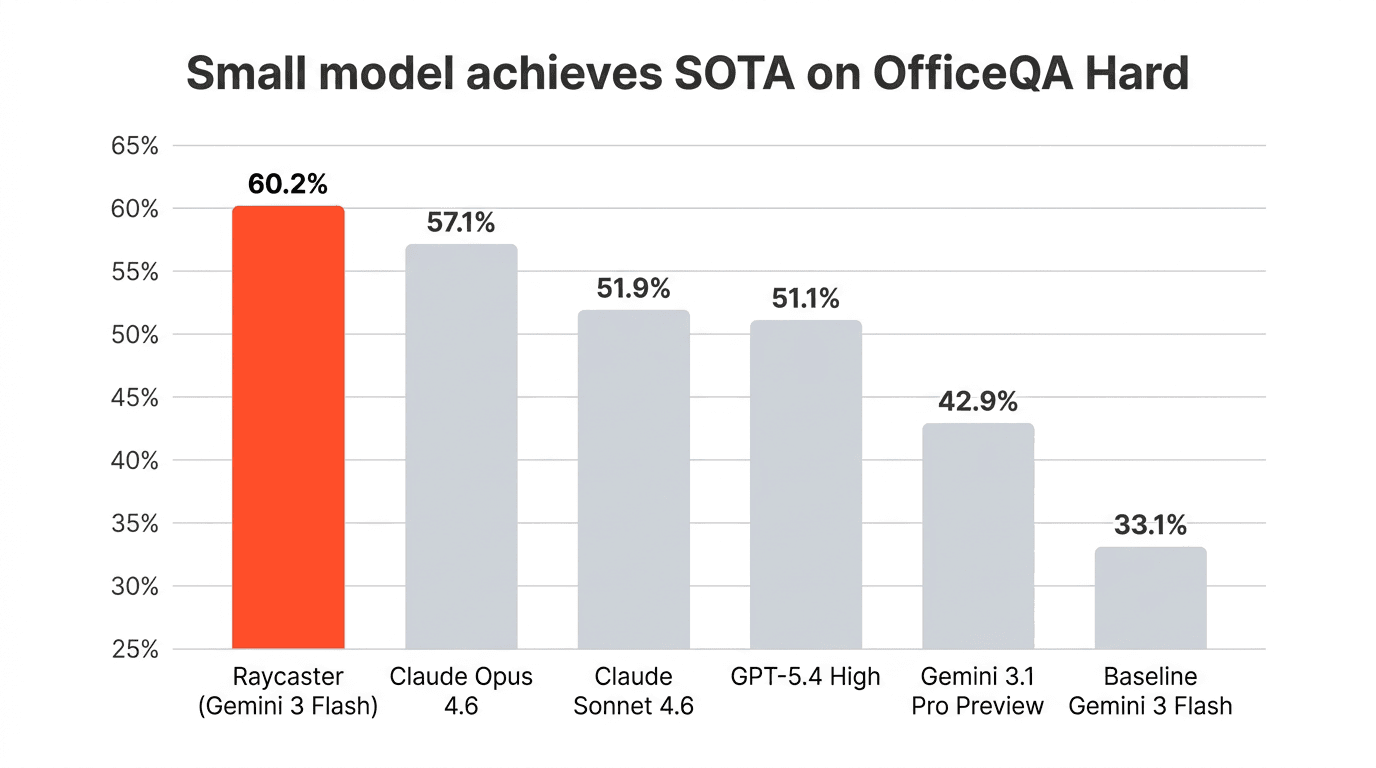
The same published parse and scoring stack; the lift comes from retrieval routing, anchoring, and harness discipline layered on top of a small model.
But accuracy is only half the equation in production. We also track the compute and latency tradeoff that affects usability. When plotting correctness scores against the average cost per question, the top-left corner represents ideal agent quality: highest performance at the lowest cost.
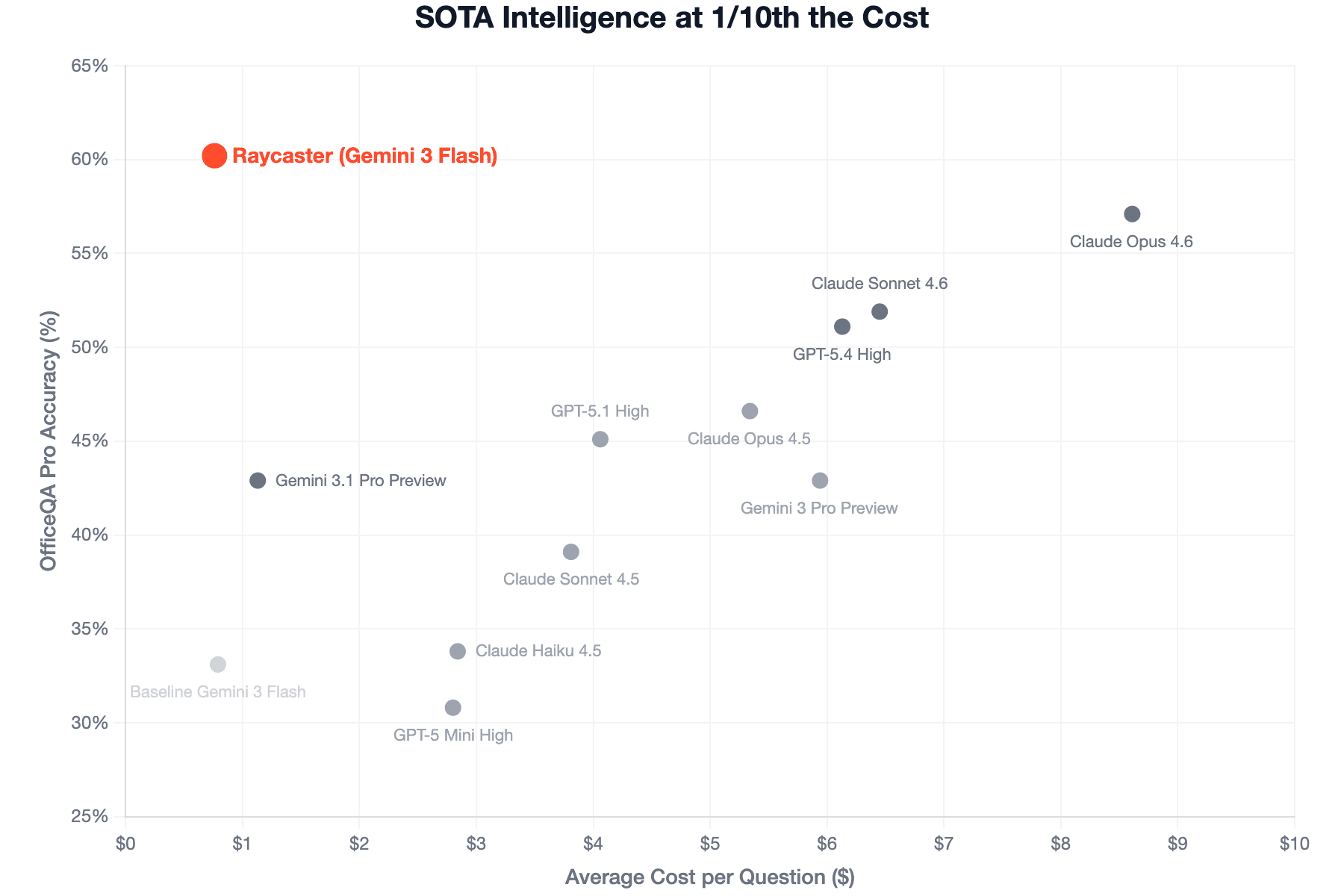
While the frontier models in the paper average anywhere from $4.00 to over $8.00 per question, the Raycaster harness running Gemini 3 Flash averages just $0.76 per question.
We read this as a clear signal: a best-in-class harness can bridge the gap between a lightweight model and frontier performance—and do so at a fraction of the cost.
The evaluation environment
Scores are summaries; the unit we care about is the trajectory. Our OfficeQA runs use an internal evaluation environment that records each task end-to-end: model, cost, latency, tool calls, retrieved files, grader verdicts, and notes. You can open the agent transcript, the grader transcript, and the tool trace side by side—so it is obvious when retrieval was right but arithmetic slipped, or when the answer matched for the wrong reason.
The panel below is a real OfficeQA task card: completed status, graded answer match, and the bulletin files the run actually pulled into context.
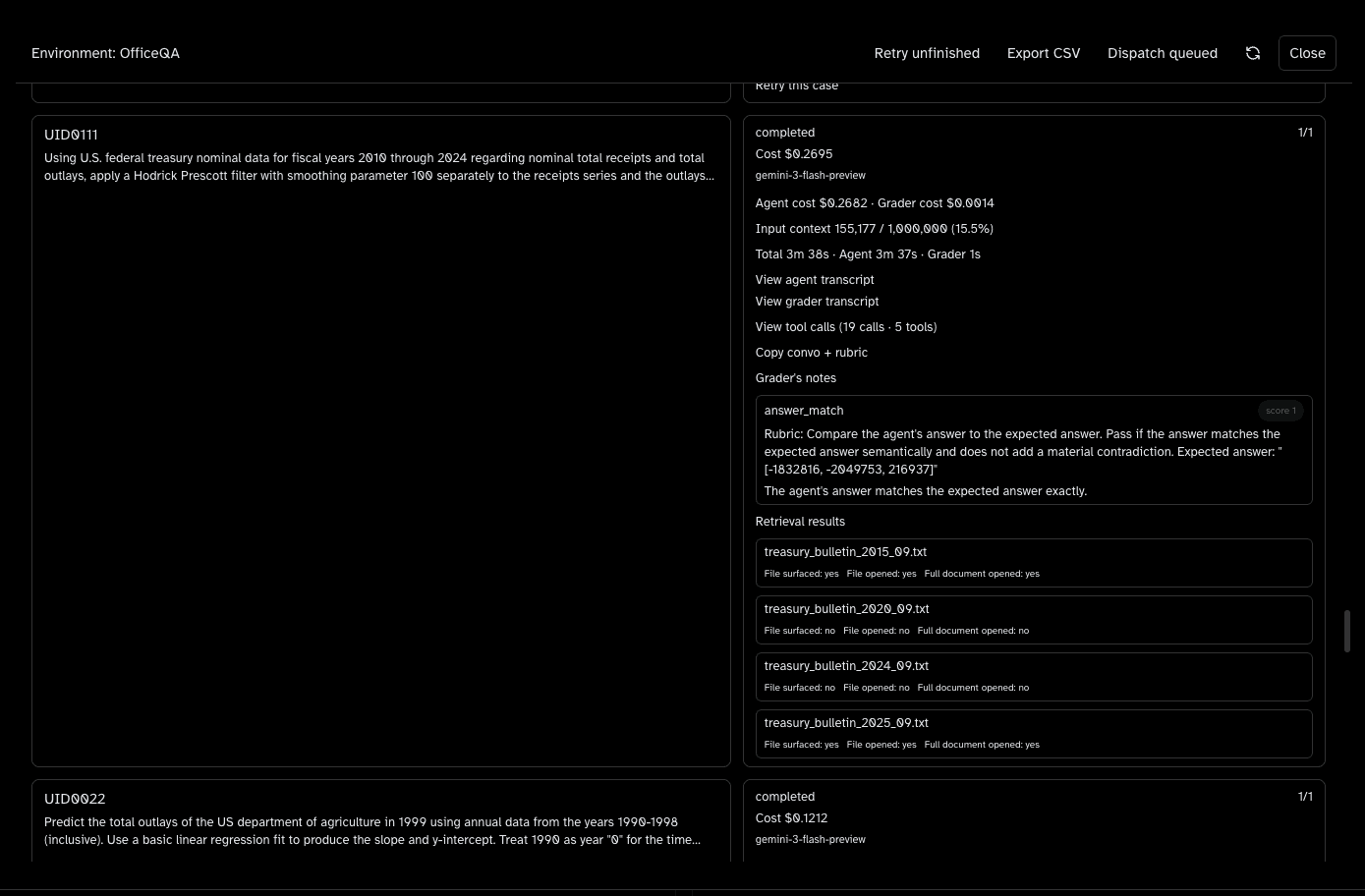
The goal is reviewability at a glance: humans should see pass/fail, evidence, and spend without spelunking raw logs.
Inside the workspace
Benchmarks summarize distributions; products have to render trajectories a reviewer can trust. The capture below is a representative slice of Raycaster on OfficeQA: the Treasury Bulletin file tree, an in-editor view of the September 1996 issue, and the whiteboard where the agent assembles fiscal-year tables before final computation.
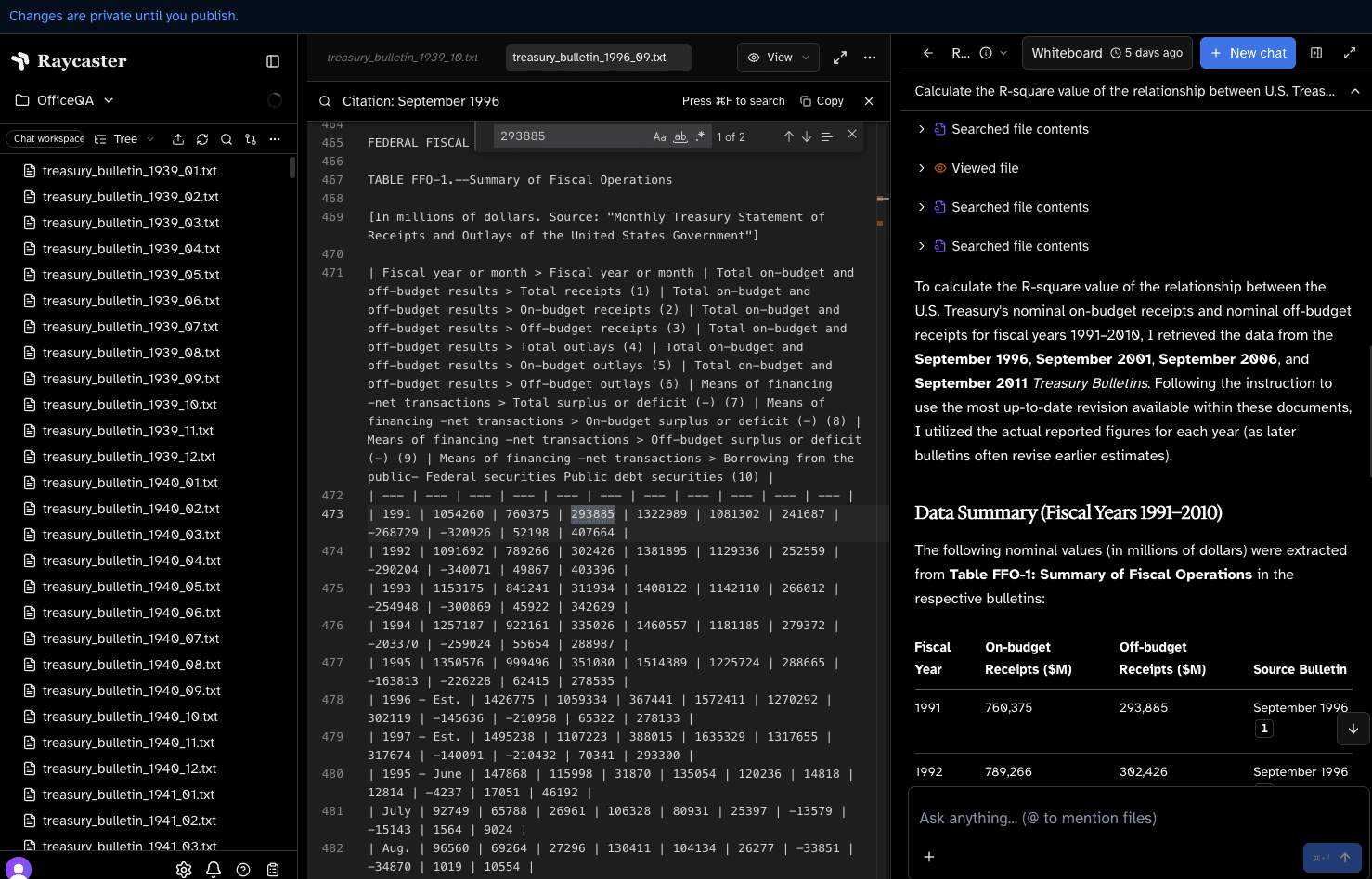
The through-line is the same as in coding agents: narrow the context, anchor symbols early, and keep intermediate artifacts visible enough that a human can verify them.
Beyond the benchmark
OfficeQA is not uniquely about Treasury bulletins. The failure modes it exposes—wrestling with heterogeneous archives, tracing amended tables, passing a merciless grader—form the exact same labyrinth found in legal, banking, consulting, biopharma, architecture, and economics.
We are not claiming that 60% accuracy on a public suite means enterprise AI is solved. But we are proving that the gap between a thin chat wrapper and a document-native runtime shows up in cold numbers. Pair a capable model with the right harness and reviewable trajectories, and you get reliability at scale—not because the model memorized the bulletins, but because the system keeps evidence and computation under control.
If your workflows look like this—dense filings, cross-issue reconciliation, and answers that must survive audit—this is the class of stack we build for production: Raycaster for Biopharma.
References and prior work
Many thanks to the OfficeQA team for the open benchmark and the public evaluation protocol—Arnav, Jaz, Ivan Zhou, Erich Elsen, Bemi, Krista Opsahl-Ong, Matei Zaharia, and everyone who contributed.
- OfficeQA Pro: An Enterprise Benchmark for End-to-End Grounded Reasoning (arXiv)
- Introducing OfficeQA (Databricks)
- APEX-Agents: evaluating long-horizon professional work (related framing for document-heavy agent benchmarks)
Partner with Raycaster
We use public suites like OfficeQA for comparable scores, but we build with customers on the corpora that actually ship in their domains. This is an invitation to build the future of document work alongside us:
- Vertical AI companies: Deploy our harness against your agents and your data—legal, banking, consulting, biopharma, architecture, economics. We run controlled splits against your chosen parsers to separate segmentation noise from actual reasoning improvements. As tasks get longer, the platform becomes the experiment: we capture edits, tool traces, reviewer acceptance, and rejection.
- Academic researchers: We are actively looking for coauthors and long-term collaborators on document engineering, grounded retrieval, HCI for agentic workspaces, and evaluation where the trajectory is the measurement unit.
- Direct customers: Work with us to close the gap between frontier capabilities and production adoption in high-stakes workflows—keeping humans in the loop without slowing the loop to a crawl.
Email team@raycaster.ai to start the conversation.
See document work the way we evaluate it
Book time to walk through retrieval, review surfaces, and change control for your team's artifacts.